
Modern platform engineering is no longer about running “a Kubernetes cluster.”
It is about operating dozens — sometimes hundreds — of clusters across multiple cloud providers, multiple regions, multiple compliance boundaries, and multiple business units.
And here’s the uncomfortable truth:
Most organizations are nowhere near ready for the operational complexity they create once they move beyond a single-cluster architecture.
The first cluster feels magical.
The tenth cluster becomes political.
The fiftieth cluster becomes existential.
At scale, the biggest problems are no longer:
- Deployments
- Containers
- CI/CD
- YAML
- Helm charts
The real problems become:
- Cluster sprawl
- Global networking
- Multi-region consistency
- Security drift
- Secret synchronization
- Cost explosions
- Control plane fragility
- Disaster recovery chaos
- Cross-cluster observability
- Policy enforcement at scale
- Organizational entropy
This is where elite platform teams separate themselves from average infrastructure organizations.
This article is a deep technical breakdown of how modern companies build resilient multi-cluster Kubernetes platforms capable of surviving:
- Region failures
- Cloud outages
- Massive scaling events
- Security incidents
- Traffic spikes
- Team autonomy conflicts
- Regulatory fragmentation
- Operational overload
We’re going to go far beyond tutorials.
This is the engineering reality behind operating Kubernetes as a global distributed platform.
Why Companies End Up With Multi-Cluster Kubernetes
At first, nearly everyone starts with one cluster.
Then reality arrives.
The Typical Evolution Path
Phase 1 — Single Cluster
Everything runs together:
- APIs
- Workers
- Frontend
- Databases
- CI/CD agents
Simple.
Cheap.
Fast.
Until:
- Blast radius grows
- Teams interfere with each other
- Upgrades become terrifying
- Networking becomes tangled
- Security isolation breaks down
Phase 2 — Environment Isolation
Organizations split:
- Dev cluster
- QA cluster
- Staging cluster
- Production cluster
This helps temporarily.
Then production scales.
Phase 3 — Regional Expansion
Now the company needs:
- US-East
- US-West
- Europe
- Asia-Pacific
Latency becomes business critical.
Phase 4 — Compliance Fragmentation
Now legal enters the conversation:
- GDPR
- HIPAA
- SOC2
- FedRAMP
- PCI-DSS
Suddenly workloads cannot coexist.
Phase 5 — Organizational Scale
Now dozens of teams want autonomy:
- Independent deployments
- Independent upgrades
- Independent networking
- Independent release cycles
Now platform engineering enters its hardest phase.
The Hidden Disaster of Multi-Cluster Complexity
Most companies dramatically underestimate this.
They think:
“We’ll just add another cluster.”
What actually happens:
Complexity Multiplies Exponentially
A single cluster has:
- One API server
- One network
- One observability stack
- One ingress layer
- One identity model
Twenty clusters create:
- Twenty control planes
- Twenty networking boundaries
- Twenty observability silos
- Twenty policy surfaces
- Twenty failure domains
The operational burden does not grow linearly.
It explodes.
The Core Architectural Models
There are several major approaches to multi-cluster Kubernetes.
Each has tradeoffs.
Model 1 — Independent Clusters
The simplest model.
Each cluster operates independently.
Architecture







Advantages
- Strong isolation
- Reduced blast radius
- Easier compliance boundaries
- Easier upgrades
Problems
- Operational duplication
- Configuration drift
- Difficult service discovery
- Complicated observability
This is where many companies stall.
Model 2 — Hub-and-Spoke Platform
A central management plane controls many workload clusters.
Architecture





This is common with:
- Platform engineering teams
- Internal developer platforms
- GitOps fleets
Benefits
- Centralized governance
- Standardized policies
- Simplified deployments
- Better visibility
Risks
- Centralized failure domains
- Platform bottlenecks
- Team autonomy conflicts
Model 3 — Federation
Clusters cooperate as one logical system.
Architecture






This enables:
- Cross-cluster scheduling
- Global service discovery
- Shared policies
- Traffic failover
But federation introduces immense operational complexity.
Most organizations underestimate this.
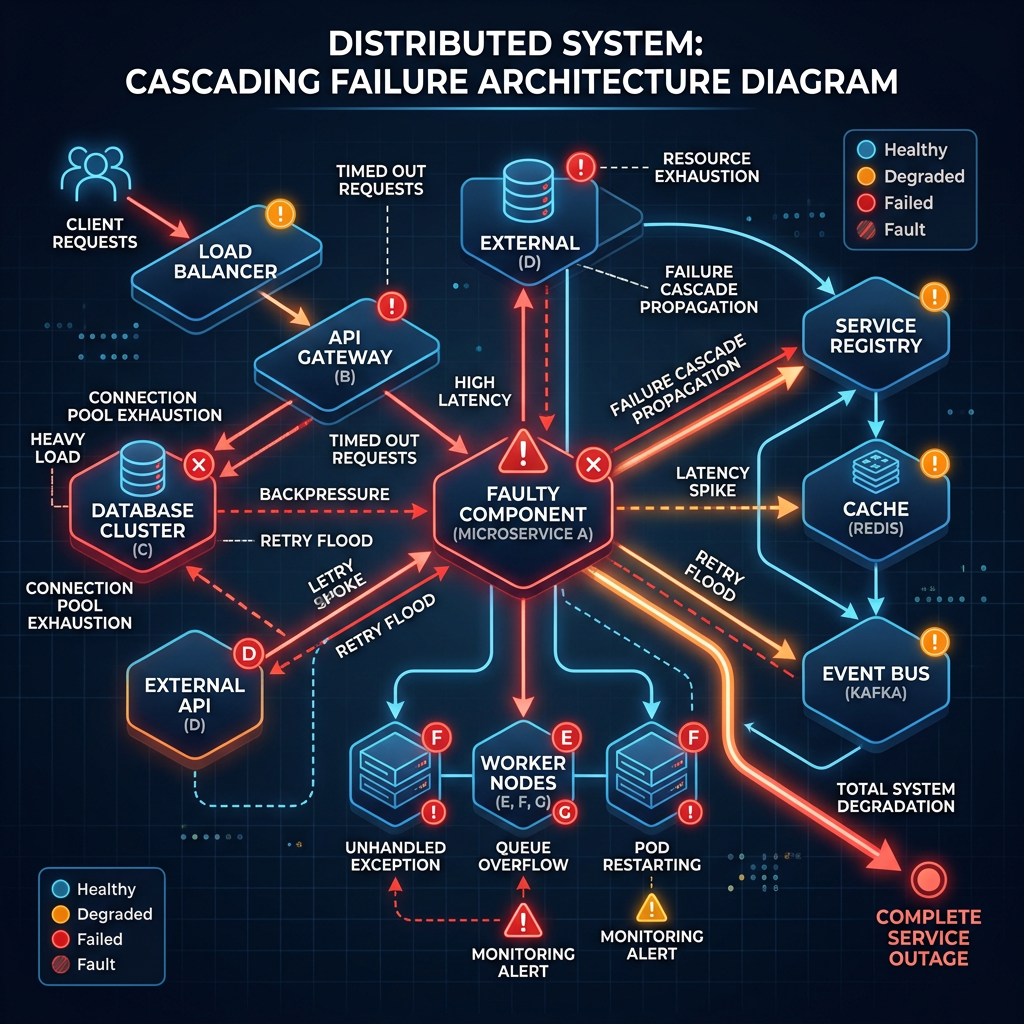
The Real Problem: Control Plane Fragility
Kubernetes itself is distributed.
But the control plane is still fragile.
Why Control Planes Fail at Scale
The Kubernetes API server becomes a bottleneck under:
- Large node counts
- Massive CRD usage
- High reconciliation traffic
- Thousands of deployments
- Aggressive controllers
Eventually:
- etcd latency spikes
- API requests queue
- Controllers fall behind
- Reconciliation loops explode
The etcd Bottleneck
etcd is often the hidden scaling ceiling.
Symptoms
- Slow deployments
- Controller instability
- Delayed node heartbeats
- API timeouts
- Cascading failures
The Reconciliation Storm
This is one of the least understood platform engineering disasters.
A reconciliation storm happens when:
- Many controllers retry simultaneously
- State drifts massively
- Network instability occurs
- API latency increases
Then:
- Controllers retry harder
- API pressure increases
- etcd becomes overloaded
- More retries occur
The platform enters positive feedback failure.
Real Production Failure Scenario
A region outage triggers:
- Thousands of pods restarting
- Massive ingress updates
- Secret synchronization
- DNS updates
- Service mesh reconvergence
Now every controller attempts reconciliation simultaneously.
The platform collapses under its own recovery behavior.
This is why resilience engineering matters more than feature engineering at scale.
Global Networking: The Hardest Problem Nobody Wants
Networking becomes brutal in multi-cluster systems.
Cross-Cluster Networking Challenges
Service Discovery
How does one service find another across clusters?
Options:
- DNS federation
- Service mesh discovery
- Global load balancers
- API gateways
Each introduces tradeoffs.
Traffic Management Complexity
East-West Traffic
Internal service communication becomes difficult:
- Latency
- MTU differences
- Encryption overhead
- Route convergence
- Cloud provider networking limitations
Multi-Region Routing
Architecture Example








Now traffic decisions depend on:
- Latency
- Region health
- Cost optimization
- Compliance boundaries
- Traffic locality
This becomes an advanced distributed systems problem.
Service Meshes: Power and Pain
Most large organizations eventually adopt service meshes.
Examples include:
- Istio
- Linkerd
- Kuma
- Consul
Why Service Meshes Exist
They solve:
- mTLS
- Traffic shaping
- Retries
- Circuit breaking
- Service discovery
- Observability
But they also add:
- Sidecar overhead
- Control plane complexity
- Certificate management
- Traffic debugging nightmares
The Sidecar Tax
Every sidecar consumes:
- CPU
- Memory
- Network
- Scheduling capacity
At scale, this becomes expensive.
A cluster with:
- 5,000 pods
- 5,000 sidecars
may consume dozens of additional nodes purely for mesh overhead.
The Security Nightmare
Security drift becomes inevitable unless aggressively managed.
The Problem with Cluster Drift
Different clusters slowly diverge:
- RBAC changes
- Network policies
- Admission controllers
- Secret policies
- Pod security standards
Eventually:
- Compliance breaks
- Security gaps emerge
- Teams behave inconsistently
GitOps Becomes Mandatory
This is why elite platform teams adopt GitOps aggressively.
Popular tools:
- ArgoCD
- FluxCD
GitOps Architecture







Git becomes:
- The source of truth
- Audit system
- Deployment engine
- Recovery mechanism
Why GitOps Wins at Scale
Without GitOps:
- Manual changes accumulate
- Drift grows
- Disaster recovery becomes impossible
With GitOps:
- Clusters become reproducible
- Rollbacks become deterministic
- Auditing becomes easier
But GitOps introduces another challenge:
- Reconciliation scale
Large fleets can overwhelm controllers.
Secrets Management Is a Disaster Waiting to Happen
This is where many companies fail audits.
The Multi-Cluster Secret Problem
Questions become difficult:
- How are secrets replicated?
- Where are encryption keys stored?
- Who rotates credentials?
- How are revocations propagated?
Common Architectures
Option 1 — Cluster-Local Secrets
Pros:
- Isolation
Cons:
- Duplication
- Rotation complexity
Option 2 — Central Secret Authority
Using:
- Vault
- AWS Secrets Manager
- Azure Key Vault
- Google Secret Manager
Architecture




This improves:
- Rotation
- Auditing
- Access control
But introduces:
- Dependency concentration
- Authentication complexity
Observability at Planet Scale
This is where many Kubernetes strategies collapse completely.
Why Observability Fails
Every cluster generates:
- Metrics
- Logs
- Traces
- Events
- Audit data
At scale:
- Cardinality explodes
- Storage costs explode
- Query latency explodes
Metrics Cardinality Disaster
Prometheus labels become dangerous.
Example:
- pod_id
- container_id
- request_path
- customer_id
Combined together:
millions of time series emerge.
This destroys observability systems.
Large-Scale Observability Architecture







Most mature organizations adopt:
- Prometheus
- Thanos
- Cortex
- Loki
- Tempo
- OpenTelemetry
OpenTelemetry Changed Everything
OpenTelemetry standardized:
- Tracing
- Metrics
- Logging instrumentation
This dramatically improved interoperability.
But implementation remains difficult.
Disaster Recovery in Multi-Cluster Systems
Most DR strategies fail in reality.
Why?
Because they are never truly tested.
The Illusion of Disaster Recovery
Many organizations believe:
- Backups exist
- Failover exists
- Runbooks exist
But under real pressure:
- DNS propagation delays occur
- Secret replication breaks
- Stateful services fail
- Databases diverge
Active-Active vs Active-Passive
Active-Passive
Simpler.
Cheaper.
But slower failover.
Active-Active





Advantages:
- Fast failover
- Better resilience
Disadvantages:
- Massive complexity
- Data consistency challenges
- Split-brain risks
Stateful Workloads Are the Real Monster
Stateless systems are easy.
Stateful systems are not.
Distributed Databases Create New Failure Modes
Examples:
- Cassandra
- CockroachDB
- Yugabyte
- MongoDB
- PostgreSQL clusters
Problems:
- Replication lag
- Network partitions
- Write consistency
- Quorum loss
CAP Theorem Becomes Reality
At small scale, CAP theorem feels academic.
At global scale, it becomes operational pain.
You must choose:
- Consistency
- Availability
- Partition tolerance
You never get all three.
Platform Engineering Teams Eventually Become Product Companies
This is a major organizational shift.
The platform itself becomes:
- A product
- A developer experience layer
- A governance engine
- A security framework
The Rise of Internal Developer Platforms (IDPs)
Modern platform teams build:
- Self-service deployment systems
- Golden paths
- Infrastructure APIs
- Service templates
IDP Architecture







This reduces:
- Cognitive load
- Operational inconsistency
- Deployment risk
The Cognitive Load Crisis
One of the biggest hidden problems in cloud-native engineering:
human scalability.
Eventually engineers cannot understand:
- Networking
- CI/CD
- Kubernetes internals
- Security policies
- Service meshes
- Observability
- IAM
- Cost optimization
simultaneously.
The stack becomes too large.
Platform engineering exists partly to reduce human overload.
The FinOps Explosion
Cloud-native systems often become financially unmanageable.
Kubernetes Encourages Waste
Why?
Because abstraction hides cost.
Developers request:
- More CPU
- More memory
- More clusters
- More replicas
because the interface makes resources feel infinite.
The Cost Multiplication Effect
Multi-cluster systems duplicate:
- Ingress controllers
- Service meshes
- Monitoring stacks
- Storage systems
- Security tooling
Now platform costs scale faster than application revenue.
How Elite Teams Reduce Cloud Waste
They aggressively optimize:
- Bin packing
- Spot workloads
- Autoscaling
- Resource quotas
- Workload scheduling
- Storage lifecycle
Autoscaling Is Harder Than People Think
HPA Problems
Horizontal Pod Autoscaler struggles with:
- Cold starts
- Burst traffic
- CPU lag
- Queue latency
Cluster Autoscaler Problems
Nodes may take:
- 2–10 minutes to appear
Too slow for sudden spikes.
Karpenter and Next-Generation Scheduling
Modern schedulers like Karpenter improved:
- Provisioning speed
- Cost efficiency
- Workload-aware scaling
But scheduling remains one of the hardest distributed systems problems in cloud-native infrastructure.
The Organizational Reality Nobody Talks About
The biggest Kubernetes failures are rarely technical.
They are organizational.
Platform Engineering Political Failure Modes
Common Problems
1. Central Platform Dictatorship
Platform teams become bottlenecks.
2. Complete Team Freedom
Chaos emerges.
3. Tooling Fragmentation
Every team invents its own platform.
4. Golden Path Rebellion
Developers bypass standards entirely.
The Best Platform Teams Understand This
The goal is not:
- Maximum control
The goal is:
- Safe autonomy
That is an enormous difference.
The Future of Multi-Cluster Kubernetes
The industry is evolving rapidly.
Emerging Trends
1. Clusterless Platforms
Users deploy workloads without seeing clusters directly.
Examples:
- Serverless Kubernetes
- Abstracted runtimes
- Platform APIs
2. eBPF Networking
eBPF is changing:
- Observability
- Security
- Networking
- Traffic analysis
Projects:
- Cilium
- Hubble
3. WASM Workloads
WebAssembly may reduce:
- Container overhead
- Startup latency
- Isolation complexity
4. AI-Assisted Operations
AI systems increasingly help with:
- Incident detection
- Root cause analysis
- Capacity planning
- Cost optimization
But AI does not eliminate platform engineering complexity.
It changes where complexity lives.
What Elite Platform Engineering Actually Looks Like
The best organizations eventually converge on several principles.
The Principles of High-Scale Kubernetes Success
1. Standardization Wins
Too much customization destroys scalability.
2. GitOps Everywhere
Manual infrastructure changes eventually become catastrophic.
3. Reduce Cognitive Load
Developer productivity matters more than infrastructure cleverness.
4. Failure Is Guaranteed
Design for:
- Region outages
- Human mistakes
- Dependency failures
- Network partitions
5. Platform Engineering Is a Product
Treat internal developers like customers.
Final Reality Check
Kubernetes is not the hard part anymore.
Operating Kubernetes globally is the hard part.
The future belongs to organizations that master:
- Distributed systems thinking
- Platform engineering
- Operational resilience
- Human scalability
- Financial discipline
- Developer experience
Because eventually:
every large technology company becomes a cloud platform company internally.
And the organizations that fail to understand this drown in their own infrastructure complexity.


















































Leave a Reply