
Introduction
Users rarely notice when software works.
They only notice when it fails.
A payment API timing out for three seconds.
A shopping cart silently losing items.
A healthcare eligibility check failing during enrollment.
A microservice retry storm taking down an entire region.
Modern software engineering isn’t just about building features.
It’s about building systems that continue operating when components fail.
And in distributed systems, failure is not an edge case.
It is the default operating condition.
This article explores the real engineering principles behind highly resilient distributed systems.
We’ll go far beyond buzzwords like:
- Circuit breakers
- Retry logic
- Failover
- Auto-scaling
Instead, we’ll examine:
- Why distributed systems fail
- Architectural resilience patterns
- Failure isolation techniques
- Load shedding strategies
- Data consistency tradeoffs
- Observability for resilience
- Chaos engineering
- Practical implementation in Java/Spring/AWS
By the end, you’ll understand how world-class engineering organizations design systems that stay operational even when parts are actively breaking.
Part 1: Why Distributed Systems Fail
Monoliths fail differently than distributed systems.
In a monolith:
A process crashes.
In distributed systems:
Failures become emergent behavior.
Small issues amplify.
A single timeout becomes:
Service A retries Service B
Service B retries Service C
Database connection pool saturates
Threads block
Latency spikes
Health checks fail
Pods restart
Traffic shifts
More retries occur
Entire platform degrades
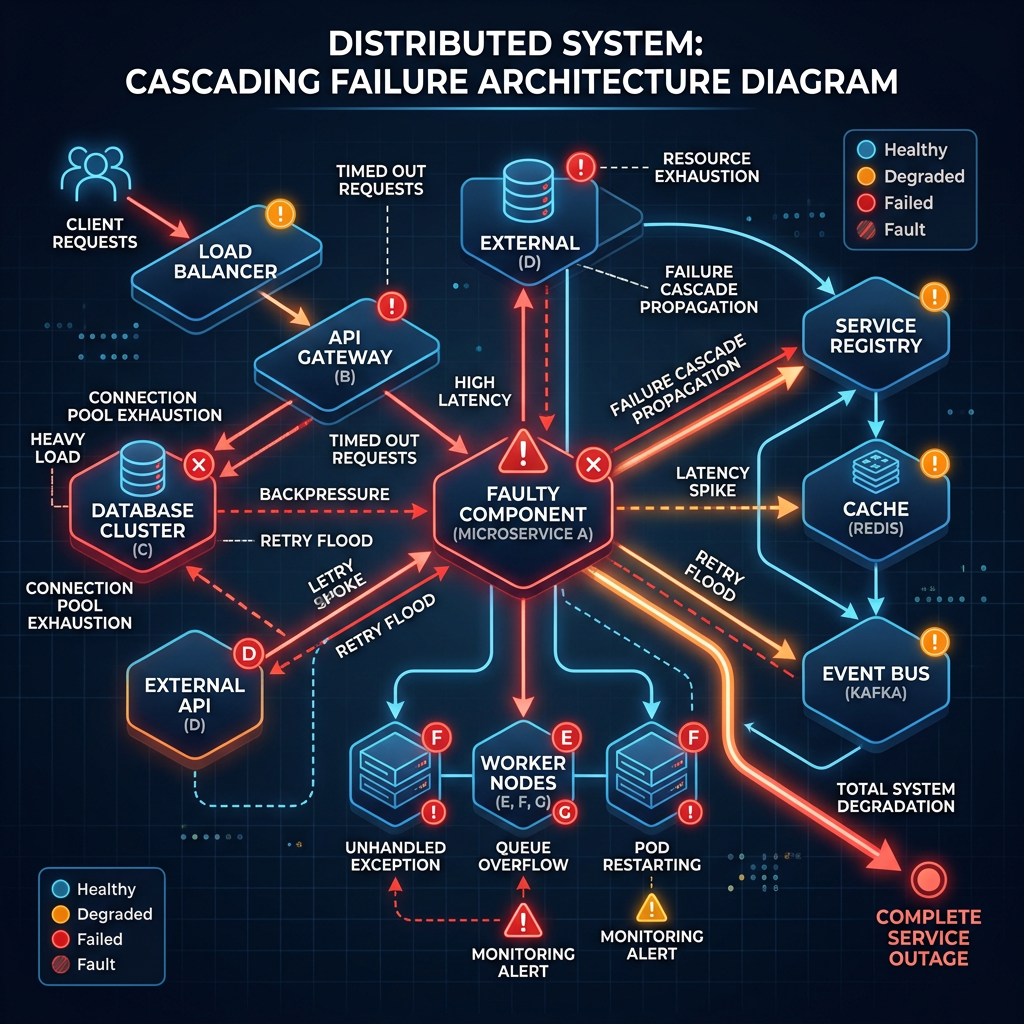
This is called failure amplification.
Diagram 1 — Failure Amplification Cascade









The hardest part of distributed systems is not normal operation.
It is non-linear degradation.
The Eight Common Failure Modes
1. Network Partition
Nodes can’t communicate.
But they’re still alive.
This creates uncertainty.
Did the request fail?
Or did the response get lost?
2. Latency Explosion
The service works.
Just slower.
Often more dangerous than outright failure.
Because systems keep retrying.
3. Resource Exhaustion
Examples:
- Thread pool exhaustion
- Memory pressure
- Connection pool saturation
- Queue growth
4. Dependency Collapse
Your service is healthy.
A downstream dependency isn’t.
You still fail.
5. Retry Storms
The most common self-inflicted outage.
6. Split Brain
Two nodes believe they’re authoritative.
Data corruption follows.
7. Configuration Drift
Different nodes behave differently.
Chaos without obvious errors.
8. Thundering Herd
Large traffic spikes after recovery.
Part 2: Designing for Failure
Resilience begins with mindset.
Weak engineering asks:
“How do we prevent failure?”
Strong engineering asks:
“How does the system behave during failure?”
That shift changes architecture.
Principle 1: Failure Must Be Isolated
Bad architecture allows failures to propagate.
Good architecture contains blast radius.
Example
Bad:
Frontend → API Gateway → Order Service → Payment Service → Inventory Service → Notification Service
Single dependency issue impacts all requests.
Good:
Each service degrades independently.
Diagram 2 — Blast Radius Containment







Isolation strategies:
Bulkheads
Separate resource pools.
Java example:
ThreadPoolTaskExecutor paymentExecutorThreadPoolTaskExecutor inventoryExecutor
Payment overload cannot starve inventory.
Queue Isolation
Dedicated queues per workflow.
Not shared queues.
Process Isolation
Critical services run independently.
Never co-host mission-critical and batch workloads.
Principle 2: Graceful Degradation
Systems should reduce functionality before failing completely.
Example:
If recommendation engine fails:
Show static recommendations.
Do not fail checkout.
Real Example
Large e-commerce systems often define service tiers:
Tier 1
Checkout
Tier 2
Cart
Tier 3
Recommendations
Tier 4
Analytics
Under pressure:
Disable lower tiers.
Preserve core business path.
Part 3: Circuit Breakers Done Right
Most teams implement circuit breakers incorrectly.
They think:
“Add library. Done.”
Reality:
Poorly tuned circuit breakers cause outages.
States
Closed
Normal operation.
Open
Requests blocked.
Half-open
Testing recovery.
Diagram 3 — Circuit Breaker State Machine





Java Spring Example
Using Resilience4j:
@CircuitBreaker(name = "paymentService")public PaymentResponse process(PaymentRequest request) { return paymentClient.process(request);}
But tuning matters.
Wrong:
failureRateThreshold: 5
Trips too aggressively.
Right:
Based on real latency/error distributions.
Part 4: Retry Logic Without Creating Outages
Retries are dangerous.
Retries multiply load.
If 10,000 requests retry 3 times:
30,000 extra requests.
Potentially during failure.
Exactly when capacity is lowest.
Correct Retry Strategy
Exponential Backoff
100ms200ms400ms800ms
Jitter
Randomization prevents synchronization.
Without jitter:
All clients retry simultaneously.
Disaster.
Diagram 4 — Retry Synchronization vs Jitter







Java example:
IntervalFunction.ofExponentialRandomBackoff( Duration.ofMillis(100), 2.0, 0.5);
Part 5: Idempotency — The Overlooked Reliability Primitive
Retries require idempotency.
Without it:
Retries create duplicates.
Examples:
Bad outcomes:
- Double charges
- Duplicate orders
- Multiple shipments
Idempotency Key Pattern
Client sends:
Idempotency-Key: 8ab2-34de
Server stores result.
Repeated request returns same response.
Diagram 5 — Idempotency Flow




Spring implementation:
@Transactionalpublic PaymentResult process(String idempotencyKey) { return repository.findByKey(idempotencyKey) .orElseGet(() -> executeAndPersist());}
Part 6: Load Shedding
When overwhelmed:
Reject work intentionally.
This feels wrong.
It is often essential.
Better:
Reject 10%
Than fail 100%.
Strategies
Token Bucket
Rate limiting.
Adaptive Concurrency
Dynamically reduce concurrency.
Priority Shedding
Drop low-priority traffic.
Example:
Drop analytics events
Preserve payments
Diagram 6 — Load Shedding Flow






Part 7: Data Consistency Under Failure
Distributed resilience is deeply tied to consistency.
CAP theorem matters.
CAP theorem
You cannot optimize for everything.
You choose.
Example Tradeoffs
Banking
Consistency first.
Availability second.
Social Feed
Availability first.
Eventual consistency acceptable.
Healthcare Eligibility Systems
Depends on operation.
Read path:
Availability
Write path:
Strong consistency
Part 8: Event-Driven Resilience
Synchronous systems are fragile.
Asynchronous systems absorb failure better.
Why Queues Improve Resilience
Queue acts as shock absorber.
Traffic spike?
Queue grows.
Consumers process steadily.
Diagram 7 — Queue-Based Shock Absorption






Technologies:
- Apache Kafka
- RabbitMQ
- Amazon SQS
Part 9: Observability for Resilience
You cannot engineer resilience blindly.
Metrics matter.
The Four Golden Signals
From Google SRE:
- Latency
- Traffic
- Errors
- Saturation
Diagram 8 — Golden Signals Dashboard







Key tools:
- Prometheus
- Grafana
- OpenTelemetry
Part 10: Chaos Engineering
Testing resilience requires failure.
Not assumptions.
This is where many teams hesitate.
That hesitation creates brittle systems.
Chaos experiments:
Kill pods
Inject latency
Drop packets
Corrupt responses
Throttle CPU
Diagram 9 — Chaos Experiment Workflow






Tools:
- Chaos Monkey
- LitmusChaos
Part 11: AWS Implementation Blueprint
For your audience, this section is gold.
Reference Architecture
API Layer:
Amazon API Gateway
Services:
Amazon ECS / Amazon EKS
Messaging:
Amazon SQS
Observability:
Amazon CloudWatch
Persistence:
Amazon DynamoDB
Diagram 10 — Resilient AWS Architecture







Part 12: Lessons From Real Production Incidents
The biggest outages often come from:
Not hardware failure.
Not software bugs.
But hidden coupling.
Examples:
- Shared connection pools
- Shared caches
- Global locks
- Synchronous dependency chains
The lesson:
Resilience is about eliminating invisible dependencies.
Part 13: Engineering Leadership Takeaways
For senior engineers and leaders:
Your job is not feature velocity alone.
It is resilience culture.
Ask in every design review:
What happens if this dependency slows?
What happens if retries amplify?
What degrades first?
What is the blast radius?
Final Thoughts
The strongest distributed systems are not those that never fail.
They are those designed to fail gracefully.
That distinction separates average engineering organizations from elite ones.
Reliability is not infrastructure.
It is architecture.
It is discipline.
It is engineering maturity.
And increasingly:
It is competitive advantage.
















































Leave a Reply